Learning Human-Like Tonal Inflections for Humanoid Robotics
Hardware design based on a mouth robot created by Professor Hideyuki Sawada from Kagawa University in Japan
Project Overview
Charlotte Avra, Maddy Weaver, Mya Chappel, Thomas Klein, Aditya Bapat
Intro to Artificial Intelligence and Machine Learning for Engineers, Carnegie Mellon University

Humanoid robots are increasingly being developed for healthcare, education and service applications. One aspect of humanoid robotics that remains an unsolved problem is achieving high fidelity lip synchronization. One potential approach to improving lip synchronization is using machine learning (ML) methods to mechanically actuate human speech sounds, linking auditory and visual output. The present work gives recommendations for improving humanoid robot hardware and software to better mimic human speech. The method includes sampling audio from the robot for testing of a convolutional neural network (CNN) trained on human audio to determine if the robot audio signals are similar to human audio signals. It was determined that limitations in pitch and tone range of both the variable pitch pneumatic sound generator and the deformable resonance tube would need to be improved. Reinforcement learning was also recommended for future research to explore more of the hardware’s abilities to produce a more human-like sound.
Individiual Contributions: All mechanical design, all , Data Acquisition, MatLab, Python, Casting and Molding, Digital Fabrication, Soft Robotics
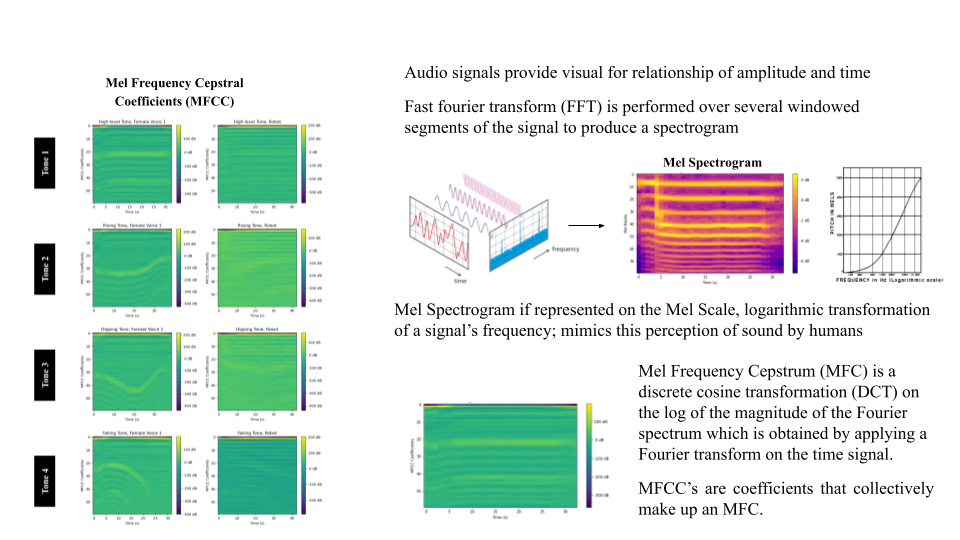
AUDIO PROCESSING
In machine learning, classifying audio signals often begins with converting from the time to frequency domains by applying a Fast Fourier Transform (FFT) over several windowed segments to produce a spectrogram, a visualization of sound with frequency and decibel level over time. If frequency is converted from Hertz to the Mel Scale, a representation of frequency that mimics the perception of sound by humans and hence why it’s used often in machine learning, the spectrogram is called a Mel Spectrogram. From there, the Mel Frequency Cepstral Coefficients can be found by applying a discrete cosine transformation and these images can be passed into a convolutional neural network to classify its various features.
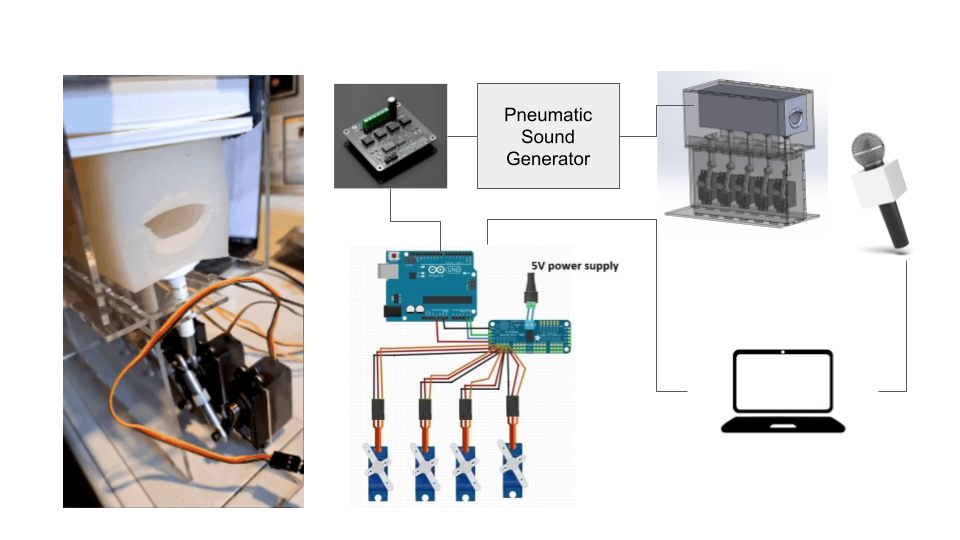
HARDWARE
We used a robotic mouth comprised of a variable pitch pneumatic sound generator, a deformable resonance tube, and a series of servo motors that can be actuated to deform the shape of the tube. The robot was controlled with an Arduino and a servo motor driver, and the produced sound data was collected through a microphone.
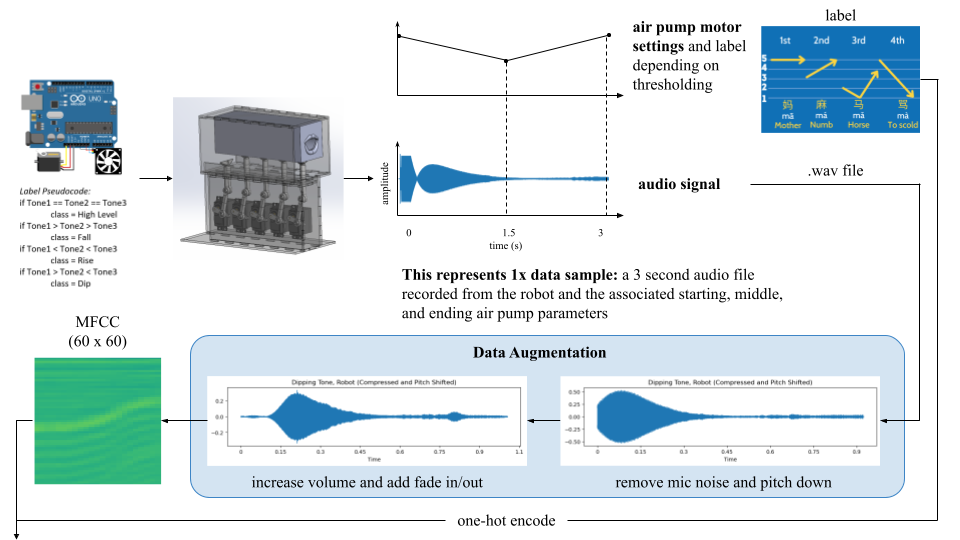
LEARNING WORKFLOW
Our goal for the scope of this project was to enable the robot to reliably produce the four words with the articulation ‘ma’ in Mandarin. To construct our dataset, we structured each data point as a sequence of 3 varied pitches with a repeating open and closed actuation of the mouth. We populated each sequence with an initial guess of the relative pitch values of a high-level, rising, dipping or a falling tone, then labeled them as such. We executed these tones on the robot and recorded the audio output.
For the data augmentation process, each audio signal was first pitched down, then increased volume, and added a fade in/fade out. 60 MFCC’s for each audio signal were then computed using the librosa sound processing library, zero padding was applied, and then they were input into the CNN.
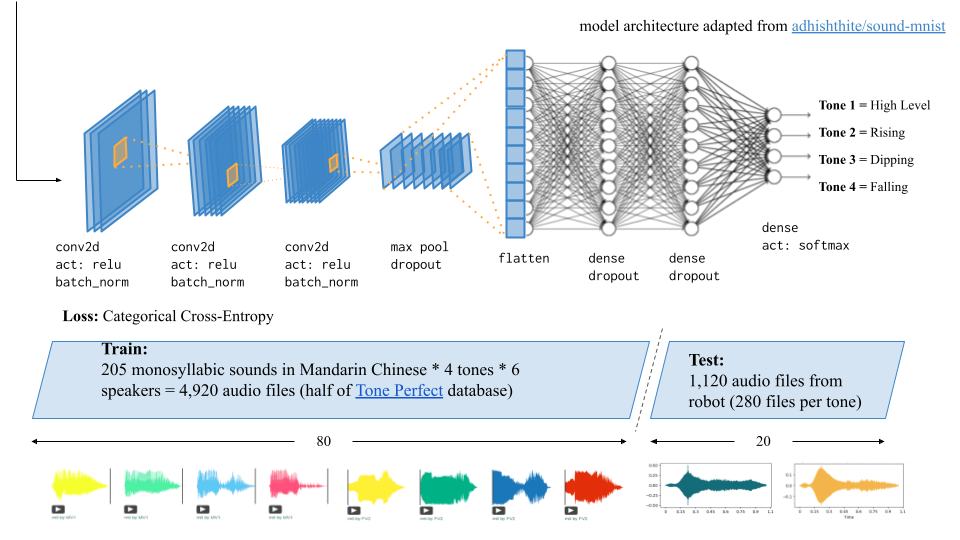
MODEL OVERVIEW
The CNN architecture we used was adapted from sound-mnist and has 3 convolution layers with relu activation and batch normalization after each layer. Then a max pooling layer and dropout followed by 3 fully connected layers the last one having softmax activation. The goal of the model was to learn from audio signals produced by humans, specifically 4,900 signals from the Tone Perfect Multimodal Database, and be tested on 1,100 audio signals produced by the robot to determine if the robot sounds were human-like. We wanted the model to generalize enough such that it could maintain high accuracy given a validation set of MFCCs that may look very different from what it was trained on, but still reflect the human-likeness of the validation set through its softmax output predictions: high value predictions for human-like sounds and low value predictions for non-human-like sounds.
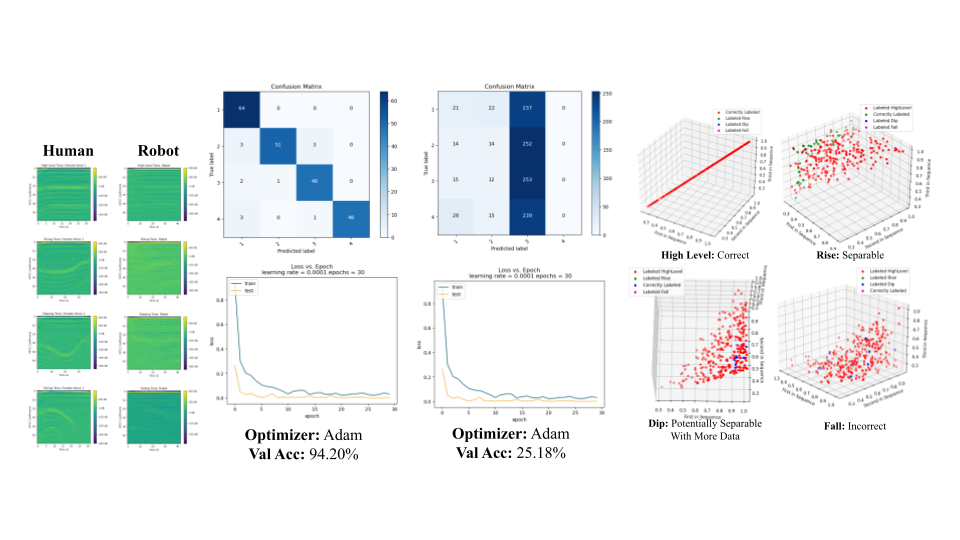
Results
We first show here four examples of the MFCC’s that the model learned and was tested on: human on the left and robot on the right. We then show model performance when trained on roughly 1,000 robot audio files. This proves that the model can successfully classify robot audio files when trained on them with 94.2% accuracy. However, when we moved to training on human audio files, the model had difficulty recognizing features in the validation set as shown here. In the 3D plots to the right, we find that for three of the four classes our correctly predicted data points are clustered and separable. This suggests that by changing the bounds of our initial guesses we could increase our accuracy. We also find that many of the correctly predicted data points fall on the edges of our plots, indicating increasing the limited tonal range of our pitch generator may increase our future success.
Keywords
CAD Design Convolutional Neural Network Data Acquisition MatLab Soft Robotics Python Mechanical Sound Generation Casting and Molding Microcontrollers Digital Fabrication Motor Drivers