It Takes Fewer Muscles to Smile Than Frown
Representing Robots with Soft Components as Graphs to Enable Surface-Aware Natural Motion
Project Overview
Madeleine Weaver, Sakthi Kumar Arul Prakash, Ananyananda Dasari, Conrad Tucker
AiPEX Lab, Carnegie Mellon University

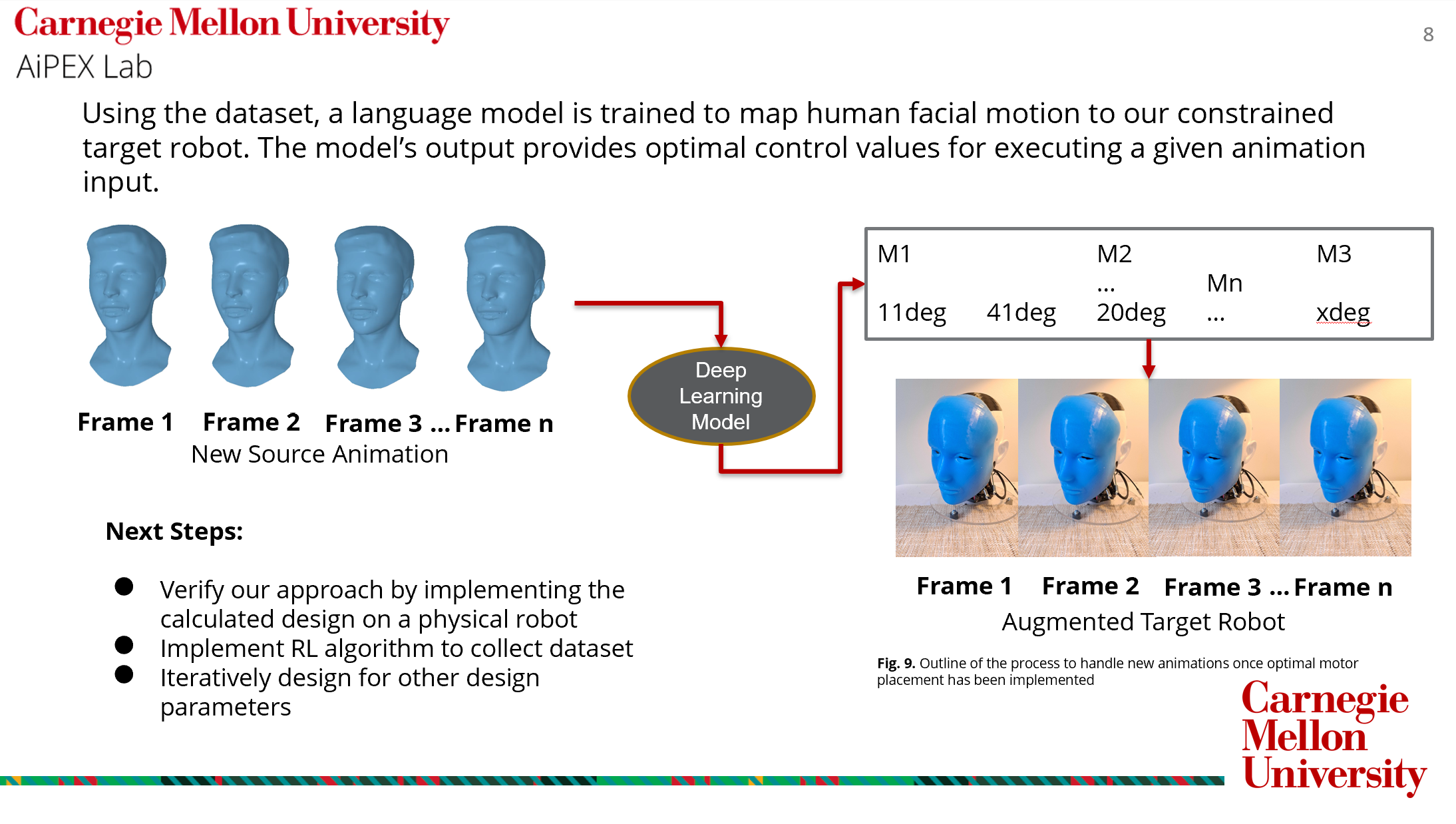
While in the computer vision domain there exist many deep learning methods to generate and retarget lip-synchronization motion to 3D models, there is presently no analogous method to retarget these 3D animations to physical robots. In this work in progress, we seek to develop a physically constrained method to co-design hardware and a controller to enable the natural animation of a robot corresponding to input speech audio.
Individual Contributions: One of two first authors, Conceptualization of research problem, 3D mesh model manipulation, Reinforcement Learning network construction and implementation.

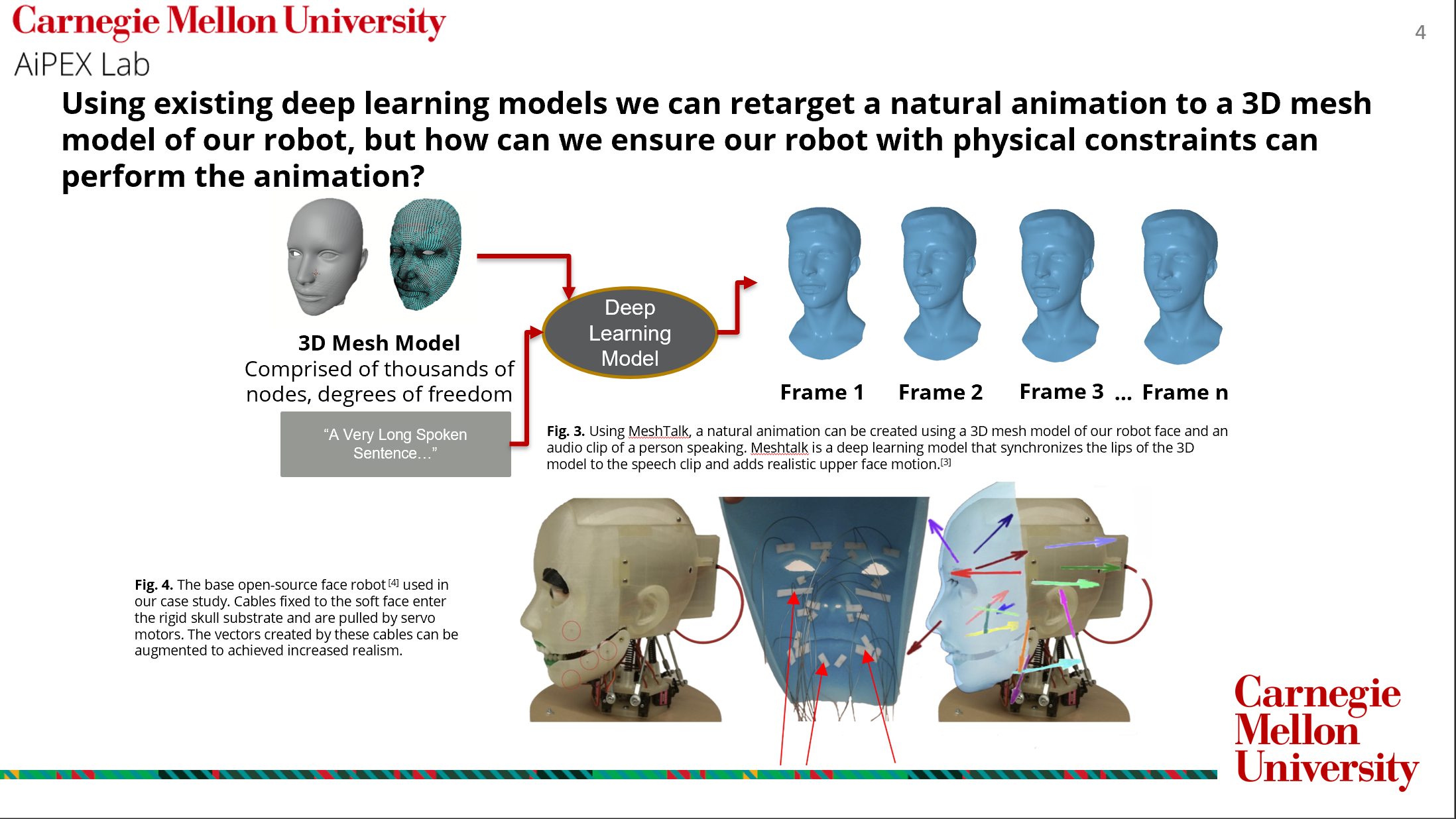
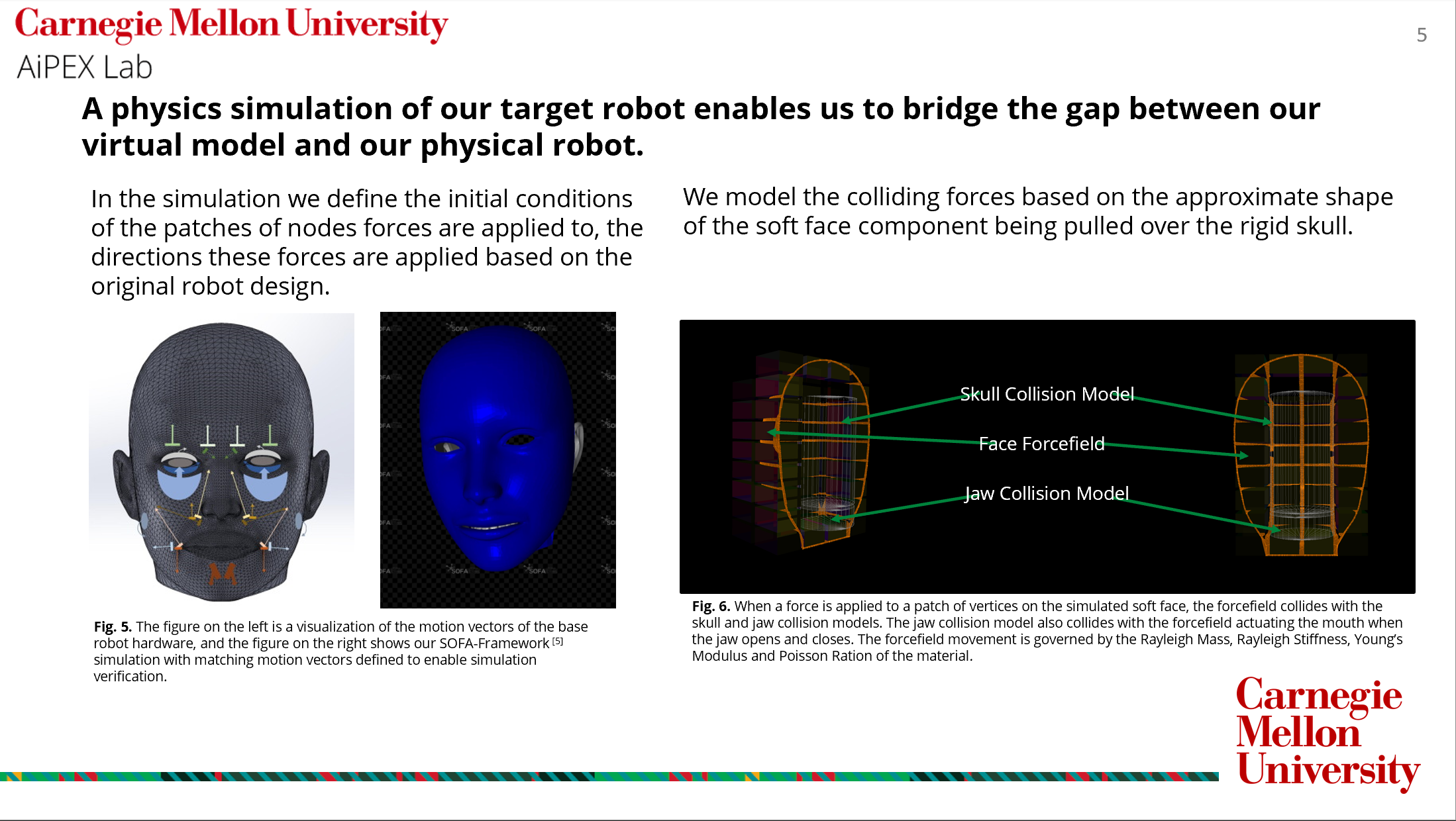
The term ‘motion retargeting’ is used to describe the practice of taking a natural motion or animation from some source by means of motion capture or 3D scanning and mapping that motion onto some target. In our case study, we use the motion of a human face as our source and a robotic representation of a human face as our target. This is a deceptively challenging task, as the dimensions of any human face or figure often do not map cleanly to the dimensions of a source robot, particularly if the designer wants to use the diverse motion of many sources. One class of solutions proposed to this problem include representing a human figure as a graph of nodes and edges that can be scaled to accommodate different forms as sources for animation. This method is effective if the success of the robot is determined by how well rigid linkages can move in synchronization with the rigid linkages of the simplified model of the human body. Another class of solutions concern the movement of the human face, which cannot be modeled with nodes and linkages but rather a series of keypoints on the face that correspond to action units. These action units describe descretized features of the face including whether the outer eyebrow, left mouth corner or right eyelid are displaced. These features are dimensionless and ignore the overall shape of the outer surface of the face, and result in an animation that is not tailored to the design of the target robot.

While in our case study we use an example of a human face, this question can be extended to many different types of robots with soft components intended to mimic human behavior. This class of robots have qualities desired in entertainment and medical spaces by virtue of the fact that they are soft and therefore particularly suited to use cases concerned with physical interaction with humans. The first of the two examples pictured is Punyo, a robot in development at Toyota Research Laboratory, whose inflatable actuators enable it to not only grasp household items like laundry baskets effectively but even grasp human bodies without crushing them to provide assistance in physical a therapy setting. The second example, the CMU arm, began as a robot designed for medical applications but later served as the inspiration for the Disney character Baymax. In each of these examples, sophisticated control methods were used to maneuver these robots but each neither included information of the deformation of the outer surface of the soft components. This information could be use to improve grasping and to enable animators to control the outer aesthetics of the robots. The hypothesis my work seeks to prove is that if we were to represent robots with soft components with a 3D mesh rather than a simplified series of lines and nodes or keypoints, we could lose less information in modeling our robots and improve their dynamics and control.